 Hispachan Files
Hispachan FilesDescargar archivos ({{ 3 }})

Version 0.2.5
{{{"lo que pasa es que quiero guardarme todo Yahoo Respuestas! ya que en unos dias mas va a desaparecer (es para conservar la pagina) pero cuando pongo el URL me empieza a guardar todo lo que hay en el servidor de Yahoo! el otro dia puse a bajar la pagina en la noche (desde el dominio answer.yahoo) y al otro dia me doy cuenta que se han bajado 10GB pero de otros servicios de Yahoo! como el Login, portales y otras cosas que no me interesan y de Yahoo Respuestas! con suerte 100kb que es el Index.\n\ncomo configuro HTTrack para que solamente guarde los vinculos que esten dentros de \"Answer.Yahoo.es\" y que todo lo que este en otro dominio que no sea eso el programa lo ignore" | renderPostMessage 84232}}}
| >> | {{{">>84232 (OP)\nHTTrack es para pendejos, muevete a autistOS (GOONO con Linocks) y usa wget." | renderPostMessage 84277}}} |
| >> | {{{">>84277\nwget no puede hacer eso, gnutard.\nY HTTrack es multiplataforma y libre." | renderPostMessage 84278}}} |
| >> | 161982757239.png [Google] [ImgOps] [iqdb] [SauceNAO] ( 6.41KB, 255x198, index.png )  {{{">>84278\n>wget no puede hacer eso, gnutard." | renderPostMessage 84280}}} |
| >> | {{{">>84280\nNo es un argumento.\nSuerte escribiendo varias líneas de shell y argumentos autistas del stdin solo para hacer una tarea simple que un programa te hace en menos tiempo kek" | renderPostMessage 84282}}} |
| >> | {{{">>84278\nexacto por eso lo uso, quiero usarlo para poreservar la pagina de Yahoo Respuestas!, la verdad es que me quedan 4 dias para guardarla y haria eso tambien por cualquier pagina que este por desaparecer" | renderPostMessage 84287}}} |
| >> | {{{">>84282\n>Suerte escribiendo varias líneas de shell\n>t dunning kruger" | renderPostMessage 84375}}} |
| >> | {{{">>84375\nya han desviado bastante mi hilo. solo quiero saber si es posible configurar algo en HTTrack para que solo me guarde la pagina de un dominio y no todo lo que esta en el servidor" | renderPostMessage 84388}}} |
| >> | {{{">>84388\nEn realidad no es que se vea muy complicado, solo añade la URL de answers.yahoo.es a la caja de direcciones web y listo. No veo por qué eso no debería no funcionar.\n>>84375\n¿Siquiera sabes qué significa Dunning Kruger y por qué lo estás aplicando?\nLo digo porque los pubertos retrasados están obsesionados con esa palabra pero no son buenos ni para emplearla correctamente, solo la usan como insulto gratuito, lo cual no es un argumento y no estás demostrando que escribir 500 líneas de shell con tus GNU coreutils y mil expresiones regulares es mejor o más eficiente que simplemente usar el programa de OP. Estás aplicando la lógica del archkid: \"me complico innecesariamente la vida y copio comandos de wikis, por lo tanto yo ser inteligente unga unga\"" | renderPostMessage 84411}}} |
| >> | {{{">>84411\n>En realidad no es que se vea muy complicado, solo añade la URL de answers.yahoo.es a la caja de direcciones web y listo. No veo por qué eso no debería no funcionar.\neso hice, pero me descarga de otros dominios como es.yahoo, mail.yahoo y todos los demas servicios siento que lo hice desde answer.yahoo por eso preguntaba si se ´podia bloquear el dominio" | renderPostMessage 84414}}} |
| >> | {{{">>84414\nPuede que algunas direcciones estén dando código HTTP 100, el cual básicamente significa \"redirige al programa a otra página\", lo que hace que se descarguen páginas que no quieres. Tal vez haya una opción para ignorar las redirecciones (o código HTTP 100).\nOtra posibilidad es que yahoo tenga un anticrawler, para lo cual debería haber una opción para falsificar el user-agent para que tu programa parezca un usuario normal de la web.\nSi te aparece una opción para cambiar user-agent, pega este texto:\nMozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4371.0 Safari/537.36\nNo te garantizo nada, pero pueden ser algunos de los errores potenciales porque pasan cuando se intentan descargar páginas de forma automática." | renderPostMessage 84416}}} |
| >> | {{{">>84416\ntienes razón Yahoo Respuestas! debe tener una barrera. ya que ahora me esta empezando a descargar paginas de otro dominio que no tiene nada que ver con Yahoo. en las opciones del HTTrack no me aparece ninguna de las opciones que dices" | renderPostMessage 84472}}} |
| >> | {{{">>84472\n>debe tener una barrera.\ntu IQ es el que tiene una barrera." | renderPostMessage 84476}}} |
| >> | {{{">>84476\ndefinitivamente no se puede guardar y a mano no es mucho lo que se puede hacer... QEPD Yahoo Respuestas!" | renderPostMessage 84511}}} |
| >> | {{{"Esa aplicación me acuerdo que se puede configurar para distintos niveles de profundidad de extracción.\n\nQuizás te sea más fácil poniéndole una regla, pero para eso deberías mirar dónde está la falla (qué direcciones descarga que no están bien y prohibirlas con las wildcards)." | renderPostMessage 84523}}} |
| >> | {{{">>84523\nanoche le puse la opcion de solo bajar links del sitio web y igual me guarda cosas nada que ver. el problema es que HTTrack no me guarda de answer.yahoo sino que guarda de otros servicios de yahoo o paginas externas por eso creo que protegieron yahoo respuestas! para que no pueda ser guardado" | renderPostMessage 84580}}} |
| >> | {{{">>84232 (OP)\ncon razón nadie descargo paginas como Jetix o tantas otras buenas que dejaron de existir por que el programa no siempre funciona. parece que solo sirve para paginas ultra-basicas que solamente tienen informacion, algo mas complejo el programa no es eficaz" | renderPostMessage 84587}}} |
| >> | {{{">>84587\n>con razón nadie descargo paginas como Jetix o tantas otras buenas que dejaron de existir por que el programa no siempre funciona. \nno, nadie lo hizo porque a nadie le importaba, no todos son unos pendejos como OPendeja." | renderPostMessage 84612}}} |
| >> | {{{">>84612\nque paginas han sido preservadas con ese programa? como te digo el programa solo me ha servido con paginas HTML simples que no tienen programación web y se descargan perfectamente. pero son paginas simples que solo tienen información de algo (a mi padre le he bajado paginas de el espacio, los planetas y todas esas paginas aburridas que no tienen ni javascript) pero paginas mas avanzadas no me ha funcionado (pero al menos he conseguido descargar algo) pero con Yahoo Respuestas! no he podido bajar nada de ese dominio como que rebota" | renderPostMessage 84630}}} |
| >> | {{{">>84232 (OP)\nLos de Archive Team ya están trabajando en eso: https://wiki.archiveteam.org/index.php/Yahoo!_Answers Lo mejor que puedes hacer es instalarte el Warrior como explican en esa pagina y aportar con tu ancho de banda y espacio en disco mientras el sitio sea todavía accesible. Es mas, si te fijas en https://tracker.archiveteam.org/yahooanswers2/ ya tienen casi 5 TB archivados por lo que al menos una buena parte del sitio sera preservada.\n>>84587\n>nadie descargo paginas como Jetix o tantas otras buenas que dejaron de existir por que el programa no siempre funciona\nCreo que eso ya es mas una cuestión cultural de no tomarse en serio la preservación de contenidos en internet (véase sino lo que paso con el primer Hispachanfiles).\n>>84630\n>que paginas han sido preservadas con ese programa?\nTengo algunas mierdas que baje hace bastante pero actualmente no uso el programa y los de Archive Team se lo bajan todo en formato WARC para luego subirlo a archive.org." | renderPostMessage 84633}}} |
| >> | {{{">>84633\nMuchas Gracias Negro. no sabia que ya estaban trabajando para preservar Yahoo Respuestas! (como lo hicieron con Geocites) estaba perdiendo el tiempo ya que se me han bajado 26GB de pura basura... jamas hubiera podido bajarme 5TB (ni tengo donde almacenar tanta cantidad de información)\n\n>>84633\n>Creo que eso ya es mas una cuestión cultural de no tomarse en serio la preservación de contenidos en internet\neso es verdad, nadie se preocupa de guardar algo que puede tener en linea (me paso recientemente con videos de pornhub que sacaron por que eran subidos por usuarios no certificados y que nunca mas he podido encontrar) desde que era niño que no entendia por que mi padre que en ese tiempo todas las paginas (en mhtml con Internet Explorer) donde había info de planetas, imagenes y todas esas cosas las guardaba (actualmente mucha de esas paginas dejaron de existir puede que mi padre solo haya guardado partes de la pagina que le gustaron pero de no haberlo hecho hubiera perdido dicha información que le interesaba de la pagina) actualmente pasa guardando videos de youtube de frank suarez (asi se llama el youtuber que ve) yo solo veo que pierde el tiempo pero puede que a futuro le sirvan" | renderPostMessage 84639}}} |
| >> | {{{">>84278\n>wget no puede hacer eso\nTécnicamente si puede, pero necesitas darle una leída al man para saber que parámetros usar, o revisar algo como https://blog.desdelinux.net/con-el-terminal-bajar-un-sitio-web-completo-con-wget/ e ir haciendo ajustes según sea necesario.\n>HTTrack es multiplataforma y libre\nIgual que wget.\n>>84287\n>haria eso tambien por cualquier pagina que este por desaparecer\nCreo que te seria mas fácil contactar a los de Archive Team en su chat ( https://wiki.archiveteam.org/index.php/Archiveteam:IRC ) cuando quieras guardar un sitio X.\n>>84639\n>me paso recientemente con videos de pornhub\nIgual a mi; lo que hice fue comenzar a bajarme todos los vídeos que aun estaban en linea un tiempo después de enterarme de todo ese mierdero que ocurrió con Mindgeek, aunque se podría decir que tuve \"suerte\" ya que de mas de 300 pude recuperar como un tercio. Con Redtube me fue mucho peor ya que de mas de 200 vídeos solo pude descargar 28, (imagino que por que la gran mayoría de usuarios no estaban validados).\nDe todos modos mucho de lo que me interesa es mas o menos recuperable ya que no era contenido amateur precisamente, por lo que cada tanto busco alguno de los vídeos borrados en Wayback Machine para intentar extraer información (como las miniaturas, actrices u otro dato relevante) y ver si tengo suerte para dar con otra versión. Por ejemplo, hace un mes pude rastrear un vídeo de Melissa Lauren que se me estaba haciendo muy difícil de encontrar.\n>todas las paginas (en mhtml con Internet Explorer) donde había info de planetas, imagenes y todas esas cosas las guardaba (actualmente mucha de esas paginas dejaron de existir puede que mi padre solo haya guardado partes de la pagina que le gustaron pero de no haberlo hecho hubiera perdido dicha información que le interesaba de la pagina)\nProbablemente esa información se pueda encontrar en miles de sitios pero quizás debería considerar subir lo que tiene a archive.org para asegurarse de que no se pierda (siempre es bueno tener algo de redundancia). Solo te haces una cuenta y metes todo en un archivo comprimido para luego subirlo como una \"colección\" al estilo de https://archive.org/details/Hispachan\n>yo solo veo que pierde el tiempo pero puede que a futuro le sirvan\nSuena como a lo de https://archive.org/details/felipegonzalezguabo ¿Quien habría creído que desaparecerían casi todos sus vídeos? Pues los primeros 4 de esa lista ya no están en Youtube y solo se pudieron rescatar por que un anon se los bajo a su disco duro en el momento justo.\nTambién esta https://altcensored.com que parece ser una buena opción para preservar canales de Youtube \"polémicos y/o controversiales\" que podrían desaparecer de un momento a otro." | renderPostMessage 84750}}} |
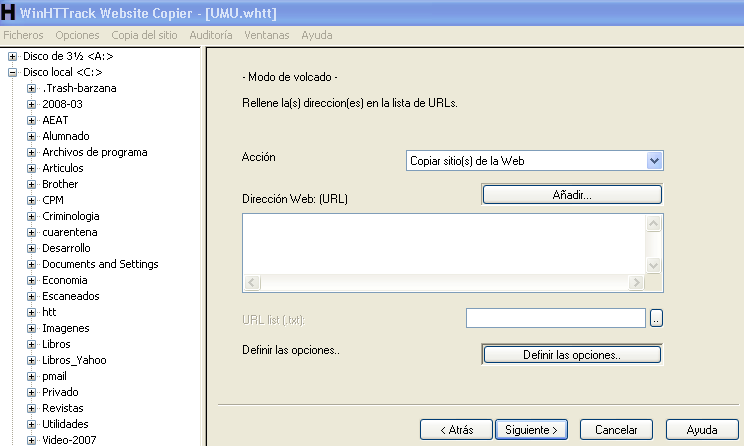
| >> | 162024350982.gif [Google] [ImgOps] [iqdb] [SauceNAO] ( 1.12MB, 1920x2204, Oh-Oh-Sherex.gif )  {{{">>84587\no es por que nadie pudo. no se si te acuerdas pero la pagina de Jetix estaba hecha a puro Flash Player. entre a WebBackMachine para recordar como era la pagina (en verdad pensaba robarle el diseño para un proyecto) tuve que instalar una extensión para habilitar Flash Player en Chrome por que sin esta no me muestra absolutamente nada. lo que note es que la mayoría de vínculos de la pagina, imágenes y todo lo que se muestran están hechos en Flash casi nada de la pagina es HTML al menos no hay una forma simple de editarlo ya que el swf esta creado con los vínculos a una dirección especifica (dominio de Jetix) cosa que guardando con HTTrack no se hubiera podido ya que solo puede detectar links en HTML pero en SWF es difícil hacerlo por eso mismo la pagina esta completamente rota en WebBackMachine. para poderse guardar la pagina tendrías que haber tenido conocimientos en Flash Player para editar los vínculos localmente (si es que se pueden editar una vez hechos) aparte viendo la pagina en un monitor de 1080p luce pésimo solamente se muestra a un costado de la pantalla ya que la pagina fue diseñada para monitores de 800x600 si nadie la guardo fue por que ni con HTTrack se podía" | renderPostMessage 84815}}} |