 Hispachan Files
Hispachan FilesDescargar archivos ({{ 5 }})

Version 0.2.5

{{{"https://github.com/josevenezuelapadron/hispachan-scraping" | renderPostMessage 36582}}}
| >> | {{{">>36582 (OP)\n\nUsa expresiones regulares." | renderPostMessage 36585}}} |
| >> | {{{">>36582 (OP)\n por que js, negro?" | renderPostMessage 36588}}} |
| >> | {{{"[code]\nwget -nd -H -p -A jpg,jpeg,png,gif -e robots=off\n[/code]\nde nada" | renderPostMessage 36590}}} |
| >> | {{{">>36590\n\nNo es lo que quiere hacer el OP." | renderPostMessage 36592}}} |
| >> | {{{"Basado, ahora añádele RegEx y te regalo tu estrellita" | renderPostMessage 36593}}} |
| >> | 154694857740.png [Google] [ImgOps] [iqdb] [SauceNAO] ( 48.44KB, 1024x874, HaQQI.png )  {{{">>36582 (OP)\nTiene muchas dependencias." | renderPostMessage 36597}}} |
| >> | {{{"Pueden hacer PR si quieren aportar algo" | renderPostMessage 36604}}} |
| >> | {{{"¿Qué tal un archivador de hilos?\n\nhttps://basc-archiver.readthedocs.io/en/stable/documents/BASC%20Fourchan%20Thread%20Archiver/" | renderPostMessage 36660}}} |
| >> | {{{">>36597\n\nno soy op pero la única dependencia que ahí me sobra es cheerio, del resto son claves, a menos que quieras el programita vainilla." | renderPostMessage 36721}}} |
| >> | {{{">>36582 (OP)\n\n>Hize\nAyyyy. Tremendo bruto el OP." | renderPostMessage 36723}}} |
| >> | {{{">>36660\nhttps://www.hispachan.org/t/res/34296.html\nYa existe." | renderPostMessage 36782}}} |
| >> | {{{">>36582 (OP)\nhttp://hispadescarga.herokuapp.com/\n\nVersión web endógena del script para descargar imágenes de los hilos, especificas la url del hilo y descargas todas las imágenes y/o archivos de este." | renderPostMessage 36958}}} |
| >> | {{{">>36958\n\n¿eres op? muy buen trabajo." | renderPostMessage 36963}}} |
| >> | {{{">>36963\nNo soy OP pero [s]robé[/s] copié su código." | renderPostMessage 36972}}} |
| >> | {{{">>36972\n\nmejor aún" | renderPostMessage 36977}}} |
| >> | {{{">>36582 (OP)\nMe tome la libertad de hacer un script básico en Python para lo mismo:\n[code]import requests, re, sys, os\n\nenlace = re.compile(\"https?://(www\\.)?hispachan\\.org/([a-z]+)/res/([0-9]+)\\.html\")\nx, tablon, idpost = enlace.match(sys.argv[1]).groups()\nadjuntos = re.compile('https://www\\.hispachan\\.org/%s/src/[0-9]+\\.[^\\'\"]+' % tablon)\npeticion = requests.get(\"https://www.hispachan.org/%s/res/%s.html\"; % (tablon, idpost))\n# Si el hilo aun existe extrae los archivos\nif peticion.status_code == 200:\n os.makedirs(os.path.join(tablon, idpost))\n for archivo in list(set(adjuntos.findall(peticion.content))):\n print \"Descargando \" + archivo\n descarga = requests.get(archivo)\n # El archivo basicamente se guarda en tablon/post/nombre\n salida = open(os.path.join(tablon, idpost, archivo.split(\"/\")[-1]), \"wb\")\n salida.write(descarga.content)\n salida.close()\nelse: print(\"El hilo no existe\")[/code]\nLas instrucciones las encuentran en https://github.com/josevenezuelapadron/hispachan-scraping/pull/2\nA diferencia del de OP, el código no es tan complejo ni tiene dependencias, aunque si quieren puedo hacer que los archivos sean guardados con su nombre real en lugar de algo como 1541089015.png pero para eso tendré que agregar algun parser como dependencia." | renderPostMessage 37699}}} |
| >> | 154848666461.png [Google] [ImgOps] [iqdb] [SauceNAO] ( 43.23KB, 1346x640, Screenshot from 2019-01-26 01-09-27.png ) 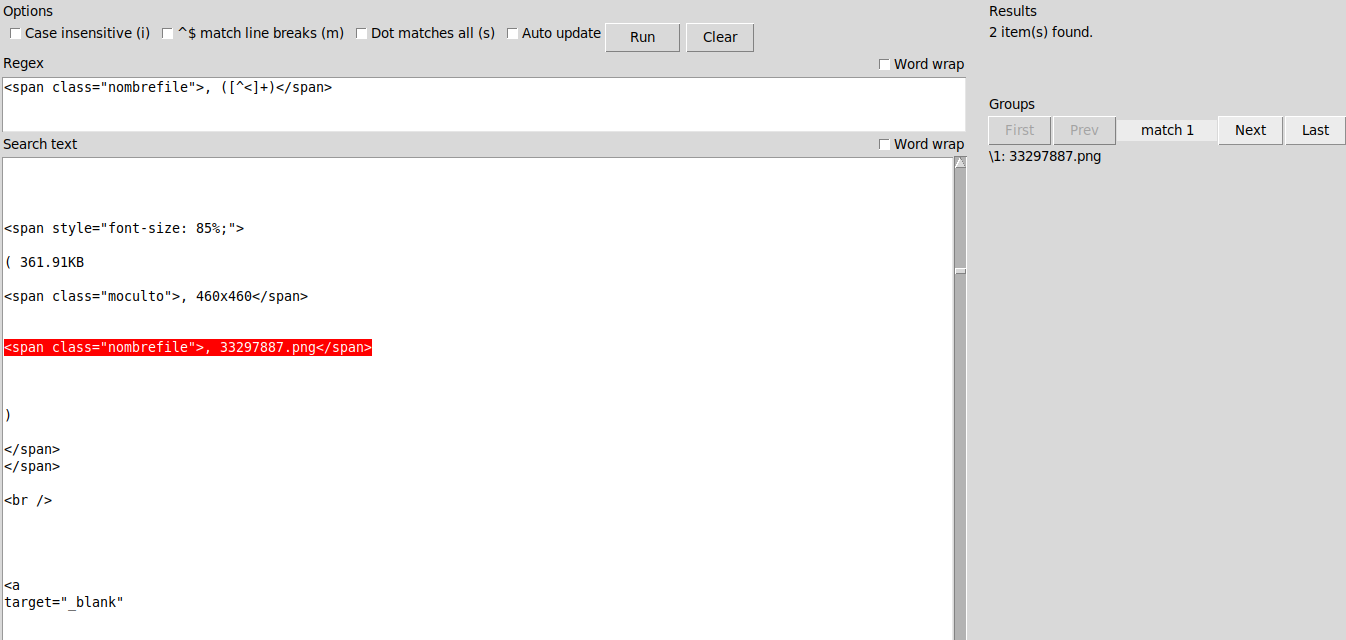 {{{">>37699\n\nMás elegante que el de OP. Para el nombre original del archivo, puedes usar el regex\n[code]<span class=\"nombrefile\">,([^<]+)</span>[/code]\nY confiar en que todo funcione porque deben venir en el mismo orden que los enlaces de descarga." | renderPostMessage 37700}}} |
| >> | {{{">>37700\nIncluso podría no usar Regex, es más elegante usar string.index()" | renderPostMessage 37707}}} |
| >> | {{{">>37700\nme gusto el codigo, ya acepte tu PR, gracias por contribuir ♥" | renderPostMessage 37719}}} |
| >> | {{{">>37720\n\nPadeces esquizofrenia negrito, pero igual gracias." | renderPostMessage 37789}}} |
| >> | {{{">>36590\nOtra forma de hacerlo con wget:\n[code]wget -r -l 1 --accept-regex \"src/.*\\.(webm|png|gif|jpg|swf|pdf|mp4)\" enlace[/code]\nA continuación explico cada uno de los parámetros:\n* [i]-r -l 1[/i]: Recursividad de nivel 1.\n* [i]--accept-regex[/i] ...: Con esto baja los archivos adjuntos de los hilos.\n* [i]enlace[/i]: Pueden ser uno o varios enlaces, o con la opción [i]-i archivo.txt[/i] descarga todos los enlaces encontrados en un archivo." | renderPostMessage 38609}}} |
| >> | {{{"Soy >>37699 y estuve haciendo algunas mejoras al script de hace unas semanas, todos los detalles están en https://github.com/josevenezuelapadron/hispachan-scraping/pull/3 y en caso de que Jose se demore en aprobar el pull request, dejo el script actualizado a continuación:\n[code]# -*- coding: utf-8 -*-\nimport requests, re, sys, os\n\nenlace = re.compile(\"https?://(www\\.)?hispachan\\.org/([a-z]+)/res/([0-9]+)\\.html\")\nx, tablon, idpost = enlace.match(sys.argv[1]).groups()\nadjuntos = re.compile('<span class=\"file(?:namereply|size)\">[\\r\\n]+<a[\\s\\r\\n]+target=\"_blank\"[\\s\\r\\n]+href=\"([^\"]+)\"(?:[\\s\\S]*?)<span class=\"nombrefile\"(?:>, ([^<]+)| title=\"([^\"]+))')\npeticion = requests.get(\"https://www.hispachan.org/%s/res/%s.html\"; % (tablon, idpost))\n# Si el hilo aun existe extrae los archivos\nif peticion.status_code == 200:\n try: os.makedirs(os.path.join(tablon, idpost))\n except OSError, e:\n if e.errno == os.errno.EEXIST:\n respuesta = raw_input(\"La carpeta donde se descargaran los archivos ya existe. ¿Desea sobreescribir los archivos? [s/n]: \")\n if respuesta in [\"n\", \"N\"]: exit(17)\n for archivo, nombre1, nombre2 in adjuntos.findall(peticion.content):\n nombre = (nombre1 if nombre2 == \"\" else nombre2)\n print(\"Descargando %s (%s)\" % (archivo, nombre))\n descarga = requests.get(archivo)\n # El archivo básicamente se guarda en tablon/post/nombre\n # Al parecer las imágenes dentro de un spoiler no contienen nombre propio\n # por lo que se usa el timestamp en su lugar\n if nombre == \"Spoiler Picture.jpg\":\n salida = open(os.path.join(tablon, idpost, archivo.split(\"/\")[-1]), \"wb\")\n else:\n salida = open(os.path.join(tablon, idpost, nombre), \"wb\")\n salida.write(descarga.content)\n salida.close()\nelse: print(\"El hilo no existe\")[/code]\n>>37700\nEl problema de buscar los nombres y enlaces por separado es que estos últimos pueden aparecer repetidos (¿para que crees que es el list(set(...)) que esta al comienzo del bloque for?) por lo que seria bastante problemático emparejar ambas cosas. De todos modos he estado trabajando en una expresión que permite extraer el nombre y enlace de un mismo \"bloque\" para solucionar esto (debería funcionar bien en la mayoría de los casos).\n>>37707\n>string.index()\n¿Y como se aplicaría en lugar de la nueva regexp que describí mas arriba?" | renderPostMessage 38666}}} |
| >> | {{{">>38666\nYa te aprobé el PR negrito, gracias por aportar, en unos días veré si le hago mantenimiento al scraper en JS" | renderPostMessage 38672}}} |
| >> | {{{">>38666\nAlgo así:\n\n[code]\n# -*- coding: utf-8 -*-\nimport sys\nimport os\nimport re\n\nimport urllib.request\nimport urllib.parse\n\n\ndef getthreadinfo(url):\n # https://www.hispachan.org/xx/res/xx.html\n r = urllib.parse.urlparse(url.lower())\n s = r.netloc\n if not (s.startswith(\"www.hispachan.org\") or s.startswith(\"hispachan.org\")):\n return None\n\n f = r.path.split(\"/\")\n if len(f) != 4:\n return None\n\n if f[2] != \"res\":\n return None\n board = f[1]\n thread = f[3].split(\".\")[0]\n if not (board or thread):\n return None\n return (board, thread)\n\n\ndef getimglist(url):\n imglist = []\n\n opener = urllib.request.build_opener()\n opener.addheaders = [\n ('User-agent', 'Mozilla/5.0')\n ]\n try:\n f = opener.open(url)\n b = f.read()\n except:\n raise\n f.close()\n\n i = 0\n while 1:\n try:\n i = b.index(b\"<span class=\\\"filesize\\\">\", i + 1)\n except ValueError:\n break\n imglist.append(i)\n\n cname = re.compile(b'href=\"[^=]+(hispachan.org.+.src.([0-9]+.+))\"')\n rname = re.compile(b'<.+class=\"nombrefile\">.?\\s+(.+)<.+>')\n\n for i in range(len(imglist)):\n name1 = cname.search(b, imglist[i], imglist[i]+1024)\n name2 = rname.search(b, imglist[i], imglist[i]+1024)\n\n r = [None, None, None]\n if name1:\n r[0] = name1.group(1).decode(\"utf-8\")\n r[1] = name1.group(2).decode(\"utf-8\")\n if name2:\n r[2] = name2.group(1).decode(\"utf-8\")\n\n imglist[i] = r\n\n return imglist\n\n\ndef saveimg(url, path, owrite):\n opener = urllib.request.build_opener()\n opener.addheaders = [\n ('User-agent', 'Mozilla/5.0')\n ]\n try:\n f = opener.open(url)\n b = f.read()\n except:\n return False\n\n # si el archivo existe intentamos con un nuevo nombre\n if not owrite and os.path.isfile(path):\n fnme, fext = os.path.splitext(path)\n\n i = 1\n while os.path.isfile(path):\n path = fnme + \"(\" + str(i) +\")\" + fext\n i += 1\n\n try:\n fh = open(path, \"wb\")\n fh.write(b)\n fh.close()\n except:\n return False\n return True\n\n\ndef saveimages(imglist, dpath, owrite):\n path = os.path.abspath(dpath)\n try:\n os.makedirs(path)\n except FileExistsError:\n pass\n \n print(\"Descargando {} imagenes en \\n[{}]\".format(len(imglist), path))\n\n f = 0\n i = len(imglist)\n for img in imglist:\n if not img[0]:\n continue\n\n link = \"https://\"; + img[0]\n name = img[1]\n if img[2]:\n name = img[2]\n name = os.path.join(path, name)\n\n if not saveimg(link, name, owrite):\n print(\"[FAIL]\", end=\"\")\n f += 1\n print(link)\n\n print(\"Terminado: imagenes descargadas {}, errores {}\".format(i - f, f))\n\n\nusage = \"\"\"\nUso: thisscript.py [opciones] <url del hilo> [<destino>]\nOpciones:\n -no-subfolder Omite la creacion de una subcarpeta para las imagenes.\n -overwrite Sobrescribe las imagenes con el mismo nombre.\n\"\"\"\n\n\ndef showusage():\n print(usage)\n exit()\n\n\nif [u]name[/u] == \"[u]main[/u]\":\n if len(sys.argv) < 2:\n showusage()\n sys.argv.pop(0)\n args = sys.argv\n\n # esto no es correcto, de este modo las opciones pueden ir en cualquier\n # posicion\n subfolder = True\n overwrite = False\n try:\n i = args.index(\"-no-subfolder\")\n args.pop(i)\n subfolder = not subfolder\n except ValueError:\n pass\n try:\n i = args.index(\"-overwrite\")\n args.pop(i)\n overwrite = not overwrite\n except ValueError:\n pass\n\n if not args or args.count(\"-overwrite\") or args.count(\"-no-subfolder\"):\n showusage()\n r = getthreadinfo(args.pop(0))\n if r:\n url = \"https://hispachan.org/{}/res/{}.html\".format(r[0], r[1])\n try:\n imglist = getimglist(url)\n if not imglist:\n print(\"Error: ninguna imagen para descargar\")\n exit()\n\n dst = os.getcwd()\n if sys.argv:\n dst = args[0]\n # \n if subfolder:\n dst = os.path.join(dst, r[0], r[1])\n saveimages(imglist, dst, overwrite)\n except Exception as e:\n print(\"Error:\", sys.exc_info()[1])\n else:\n print(\"Error: url invalida\")\n[/code]" | renderPostMessage 38675}}} |
| >> | {{{">>38666\n>El problema de buscar los nombres y enlaces por separado es que estos últimos pueden aparecer repetidos (¿para que crees que es el list(set(...)) que esta al comienzo del bloque for?) por lo que seria bastante problemático emparejar ambas cosas. De todos modos he estado trabajando en una expresión que permite extraer el nombre y enlace de un mismo \"bloque\" para solucionar esto (debería funcionar bien en la mayoría de los casos). \n\nNo hay razón para que no estén en el mismo orden." | renderPostMessage 38680}}} |
| >> | {{{">>38675\nUn arreglo:\n[code]\n\ndef getimglist(url):\n imglist = []\n\n opener = urllib.request.build_opener()\n opener.addheaders = [\n ('User-agent', 'Mozilla/5.0')\n ]\n try:\n f = opener.open(url)\n b = f.read()\n except:\n raise\n f.close()\n\n i = 0\n while 1:\n try:\n i = b.index(b\"<span class=\\\"filesize\\\">\", i + 1)\n except ValueError:\n break\n imglist.append(i)\n\n cname = re.compile(b'href=\"[^=]+(hispachan.org.+.src.(.+.+))\"')\n rname = re.compile(b'<.+class=\"nombrefile\"(?: title=\"(.+)\")?>.?\\s+(.+)<.+>')\n\n for i in range(len(imglist)):\n name1 = cname.search(b, imglist[i], imglist[i]+1024)\n name2 = rname.search(b, imglist[i], imglist[i]+1024)\n\n r = [None, None, None]\n if name1:\n r[0] = name1.group(1).decode(\"utf-8\")\n r[1] = name1.group(2).decode(\"utf-8\")\n if name2:\n if name2.group(1):\n r[2] = name2.group(1).decode(\"utf-8\")\n else:\n r[2] = name2.group(2).decode(\"utf-8\")\n\n imglist[i] = r\n\n return imglist\n[/code]" | renderPostMessage 38688}}} |
| >> | {{{">>38688\n\nAñadido los request/descargas en paralelo y la flag \"-update\" para actualizar los archivos en algún hilo.\n\n[code]\n# -*- coding: utf-8 -*-\nimport sys\nimport os\nimport re\nimport threading\nimport queue\nimport time\n\nimport urllib.request\nimport urllib.parse\nimport urllib.error\n\n\nURLError = urllib.error.URLError\n\n\n# flags\nsubfolder = None\noverwrite = None\nupdate = None\n\n# shared stuff\nnbitsmutx = threading.Lock()\nnbits = 0\n\n\ndef getthreadinfo(url):\n # https://www.hispachan.org/xx/res/xx.html\n if not url:\n return None\n\n r = urllib.parse.urlparse(url.lower())\n s = r.netloc\n if not (s.startswith(\"www.hispachan.org\") or s.startswith(\"hispachan.org\")):\n f = url.split(\"/\")\n if len(f) == 2:\n return f\n return None\n\n f = r.path.split(\"/\")\n if len(f) != 4:\n return None\n\n if f[2] != \"res\":\n return None\n board = f[1]\n thread = f[3].split(\".\")[0]\n if not (board or thread):\n return None\n return (board, thread)\n\n\ndef getimglist(url):\n imglist = []\n\n opener = urllib.request.build_opener()\n opener.addheaders = [\n ('User-agent', 'Mozilla/5.0')\n ]\n try:\n f = opener.open(url, timeout=20)\n b = f.read()\n except URLError:\n raise\n f.close()\n\n i = 0\n while 1:\n try:\n i = b.index(b\"<span class=\\\"filesize\\\">\", i + 1)\n except ValueError:\n break\n imglist.append(i)\n\n cname = re.compile(b'href=\"[^=]+(hispachan.org.+.src.(.+.+))\"')\n rname = re.compile(b'<.+class=\"nombrefile\"(?: title=\"(.+)\")?>.?\\s+(.+)<.+>')\n\n for i in range(len(imglist)):\n name1 = cname.search(b, imglist[i], imglist[i]+1024)\n name2 = rname.search(b, imglist[i], imglist[i]+1024)\n\n r = [None, None, None]\n if name1:\n r[0] = name1.group(1).decode(\"utf-8\")\n r[1] = name1.group(2).decode(\"utf-8\")\n if name2:\n if name2.group(1):\n r[2] = name2.group(1).decode(\"utf-8\")\n else:\n r[2] = name2.group(2).decode(\"utf-8\")\n\n imglist[i] = r\n\n return imglist\n\n\ndef subprocess(iqueue, oqueue):\n while True:\n tmp = iqueue.get()\n if not tmp:\n break\n\n if saveimg(tmp[0], tmp[1]):\n oqueue.put((tmp[0], True))\n continue\n oqueue.put((tmp[0], False))\n\n\ndef saveimg(url, path):\n global nbits\n global nbitsmutx\n\n opener = urllib.request.build_opener()\n opener.addheaders = [\n ('User-agent', 'Mozilla/5.0')\n ]\n try:\n f = opener.open(url, timeout=120)\n except URLError:\n return False\n except:\n return False\n\n if os.path.isfile(path):\n if update:\n try:\n sz1 = int(f.info()[\"Content-Length\"])\n\n fh = open(path, \"rb\")\n fh.seek(0, 2)\n sz2 = fh.tell()\n fh.close()\n except:\n return False\n\n if sz1 == sz2:\n return True\n\n # si el archivo existe intentamos con un nuevo nombre\n if not update and not overwrite:\n fnme, fext = os.path.splitext(path)\n\n i = 1\n while os.path.isfile(path):\n path = fnme + \"(\" + str(i) +\")\" + fext\n i += 1\n\n try:\n fh = open(path, \"wb\")\n while True:\n b = f.read(4096)\n if not b:\n break\n\n nbitsmutx.acquire()\n nbits += len(b)\n nbitsmutx.release()\n\n fh.write(b)\n fh.close()\n except (IOError, URLError):\n return False\n except:\n return False\n return True\n\n\ndef saveimages(ilist, dpath):\n global nbits\n\n path = os.path.abspath(dpath)\n try:\n os.makedirs(path)\n except FileExistsError:\n pass\n\n print(\"Descargando {} imagenes en \\n[{}]\".format(len(ilist), path))\n\n iqueue = queue.Queue()\n oqueue = queue.Queue()\n\n threads = []\n for i in range(4):\n thr = threading.Thread(target=subprocess, args=(iqueue, oqueue))\n thr.daemon = True\n thr.start()\n threads.append(thr)\n\n for img in ilist:\n if not img[0]:\n continue\n\n link = \"https://\"; + img[0]\n name = img[1]\n if img[2]:\n name = img[2]\n iqueue.put((link, os.path.join(path, name)))\n\n f = 0\n i = 0\n try:\n while i < len(ilist):\n while not oqueue.empty():\n r = oqueue.get()\n \n print(\"\\r...\" + r[0][8:], end=\" \")\n if not r[1]:\n print(\"[FAILED]\", end=\"\")\n f += 1\n print()\n i += 1\n\n print(\"\\r{}Kb\".format(nbits >> 10), end=\"\")\n time.sleep(0.15)\n except KeyboardInterrupt:\n exit()\n\n print(\"\\r{}Kb\".format(nbits >> 10))\n print(\"Terminado: archivos descargados {}, errores {}\".format(i - f, f))\n\n\nusage = \"\"\"\nUso: thisscript.py [opciones] <url del hilo o tablon/hilo> [<destino>]\nOpciones:\n -no-subfolder Omite la creacion de una subcarpeta para las imagenes.\n -overwrite Sobrescribe los archivos con el mismo nombre.\n -update Solo descarga los archivos que no existen.\n\"\"\"\n\n\ndef showusage():\n print(usage)\n exit()\n\n\nif [u]name[/u] == \"[u]main[/u]\":\n if len(sys.argv) < 2:\n showusage()\n sys.argv.pop(0)\n args = sys.argv\n\n # parametros\n options = {\n \"-no-subfolder\": (\"subfolder\", True),\n \"-overwrite\": (\"overwrite\", False),\n \"-update\": (\"update\", False)\n }\n\n s = globals()\n for option in options:\n m = options[option]\n s[m[0]] = m[1]\n\n while args[0] in options:\n a = args.pop(0)\n if not options[a]: # parametro duplicado\n showusage()\n s[options[a][0]] = not options[a][1]\n options[a] = None\n\n if not args or len(args) > 2:\n showusage()\n\n r = getthreadinfo(args.pop(0))\n if not r:\n print(\"Error: url invalida\")\n\n url = \"https://hispachan.org/{}/res/{}.html\".format(r[0], r[1])\n try:\n ilist = getimglist(url)\n if not ilist:\n print(\"Error: ningun archivo para descargar\")\n exit()\n\n dpath = os.getcwd()\n if args:\n dpath = args[0]\n #\n if subfolder:\n dpath = os.path.join(dpath, r[0], r[1])\n saveimages(ilist, dpath)\n except KeyboardInterrupt:\n exit()\n except Exception as e:\n print(\"Error:\", e)\n\n[/code]" | renderPostMessage 38824}}} |
| >> | 155045745621.png [Google] [ImgOps] [iqdb] [SauceNAO] ( 38.14KB, 752x456, Screenshot from 2019-02-17 20-34-12_.png ) 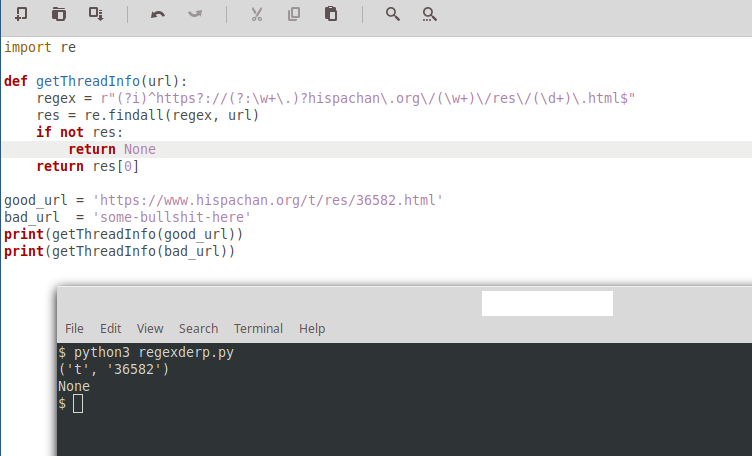 {{{">>38824\n\n¿Por qué odias tanto las expresiones regulares? ¿Eres el mongol del hilo de Vim que argumentaba que no son buenas porque \"son complicadas\"? Tu función getthreadinfo() podría simplificarse ampliamente." | renderPostMessage 38826}}} |
| >> | {{{">>38826\nSe ve fea anón, muchas barras invertidas.\n\n[code]\nregex = \"(?i)^(?:(?:(?:(?:https?://)?(?:[a-z]+[.])?)?hispachan[.]org/)?|/?)?([a-z]+)/(?:res/)?([0-9]+)(?:[.]html)?\"\n[/code]" | renderPostMessage 38877}}} |
| >> | {{{">>38826\n>Tu función getthreadinfo() podría simplificarse ampliamente.\nAdemás de eso, usar expresiones regulares en lugar de urllib.parse para parsear el enlace también resulta ser mas eficiente. ¿Que tanto? Casi tres veces mas rápido según mis pruebas. Para comprobarlo pueden ejecutar este código (ya sea en una consola o en sitios como https://www.onlinegdb.com/ ):\n[code]import timeit\nimport urllib.parse\n\ndef getthreadinfo():\n url= \"https://www.hispachan.org/t/res/36582.html\";\n if not url:\n return None\n \n r = urllib.parse.urlparse(url.lower())\n s = r.netloc\n if not (s.startswith(\"www.hispachan.org\") or s.startswith(\"hispachan.org\")):\n f = url.split(\"/\")\n if len(f) == 2:\n return f\n return None\n \n f = r.path.split(\"/\")\n if len(f) != 4:\n return None\n \n if f[2] != \"res\":\n return None\n board = f[1]\n thread = f[3].split(\".\")[0]\n if not (board or thread):\n return None\n return (board, thread)\n\ndef getThreadInfo():\n url= \"https://www.hispachan.org/t/res/36582.html\";\n regex = r\"(?i)^https?://(?:\\w+\\.)?hispachan\\.org\\/(\\w+)\\/res\\/(\\d+)\\.html\"\n res = re.findall(regex, url)\n if not res:\n return None\n return res[0]\n\ntimeit.timeit(getthreadinfo)\ntimeit.timeit(getThreadInfo)[/code]\nTuve que agregar el enlace dentro de las funciones ya que no puedo pasarlo como parámetro desde timeit.\nPor cierto, esto se puede optimizar aun mas compilando el patrón (algo que se recomienda si se piensa usar varias veces) por lo que el código quedaría así:\n[code]import re\n\nregex = re.compile(r\"(?i)^https?://(?:\\w+\\.)?hispachan\\.org\\/(\\w+)\\/res\\/(\\d+)\\.html\")\n\ndef getThreadInfo():\n url= \"https://www.hispachan.org/t/res/36582.html\";\n res = regex.findall(url)\n if not res:\n return None\n return res[0][/code]\nQuizás en un script simple no importe mucho, pero si después alguien quiere hacer una versión web como la de >>36958 entonces cualquier mejora en el desempeño ayuda." | renderPostMessage 39454}}} |
| >> | {{{">>39454\n>usar expresiones regulares en lugar de urllib.parse para parsear el enlace también resulta ser mas eficiente. ¿Que tanto? Casi tres veces mas rápido según mis pruebas.\nTambién hice pruebas y sí, resulta más rápido. Pero no estás usando el regex correcto, la función original getthreadinfo captura el id del tablón y el id del hilo tanto en la forma del url completa o en la forma corta: \"/tablón/hilo\". El regex seria este >>38877 no hay diferencia, pero la diferencia en la performance es mínima, se pierde más tiempo en hacer el request entre descarga y descarga." | renderPostMessage 39458}}} |
| >> | {{{">>36582 (OP)\nAnones acabo de actualizar el repo, ahora el código es mucho mas legible, hice una rama independiente para el script de python, cabe aclarar que ese script no lo hice yo y por lo tanto no le daré mantenimiento" | renderPostMessage 39752}}} |
| >> | {{{">>38824\nSoy el de >>38666 que había hecho el script básico. Sin duda el tuyo te quedo muy bien y es bastante completo (bastante impresionante lo de las descargas concurrentes). Espero que no te importe que haya fusionado ambos scripts y le enviara un commit a Jose con el resultado (en https://github.com/josevenezuelapadron/hispachan-scraping/pull/4 se pueden ver los detalles). También lo dejo a continuación para quien quiera ver como quedo:\n[code]# -*- coding: utf-8 -*-\nimport sys\nimport os\nimport re\nimport threading\nimport queue\nimport time\n\nimport urllib.request\nimport urllib.error\n\nURLError = urllib.error.URLError# flags\nsubfolder = None\noverwrite = None\nupdate = None\n\n# shared stuff\nnbitsmutx = threading.Lock()\nnbits = 0\n\n# Expresiones regulares para evitar escribir codigo innecesariamente complejo\nadjuntos = re.compile('<span class=\"file(?:namereply|size)\">[\\r\\n]+<a[\\s\\r\\n]+target=\"_blank\"[\\s\\r\\n]+href=\"([^\"]+)\"(?:[\\s\\S]*?)<span class=\"nombrefile\"(?:>, ([^<]+)| title=\"([^\"]+))')\nenlace = re.compile(\"https?://(?:www\\.)?hispachan\\.org/([a-z]+)/res/([0-9]+)\\.html\")\n\ndef getthreadinfo(url):\n board, thread = enlace.match(url).groups()\n return (board, thread)def getimglist(url):\n opener = urllib.request.build_opener()\n opener.addheaders = [\n ('User-agent', 'Mozilla/5.0')\n ]\n try:\n f = opener.open(url, timeout=20)\n b = f.read()\n except URLError:\n raise\n f.close()\n\n return adjuntos.findall(b.decode('utf-8'))def subprocess(iqueue, oqueue):\n while True:\n tmp = iqueue.get()\n if not tmp:\n break\n\n if saveimg(tmp[0], tmp[1]):\n oqueue.put((tmp[0], True))\n continue\n oqueue.put((tmp[0], False))def saveimg(url, path):\n global nbits\n global nbitsmutx\n\n opener = urllib.request.build_opener()\n opener.addheaders = [\n ('User-agent', 'Mozilla/5.0')\n ]\n try:\n f = opener.open(url, timeout=120)\n except URLError:\n return False\n except:\n return False\n\n if os.path.isfile(path):\n if update:\n try:\n sz1 = int(f.info()[\"Content-Length\"])\n\n fh = open(path, \"rb\")\n fh.seek(0, 2)\n sz2 = fh.tell()\n fh.close()\n except:\n return False\n\n if sz1 == sz2:\n return True\n\n # si el archivo existe intentamos con un nuevo nombre\n if not update and not overwrite:\n fnme, fext = os.path.splitext(path)\n\n i = 1\n while os.path.isfile(path):\n path = fnme + \"(\" + str(i) +\")\" + fext\n i += 1\n\n try:\n fh = open(path, \"wb\")\n while True:\n b = f.read(4096)\n if not b:\n break\n\n nbitsmutx.acquire()\n nbits += len(b)\n nbitsmutx.release()\n\n fh.write(b)\n fh.close()\n except (IOError, URLError):\n return False\n except:\n return False\n return Truedef saveimages(ilist, dpath):\n global nbits\n\n path = os.path.abspath(dpath)\n try:\n os.makedirs(path)\n except FileExistsError:\n pass\n\n print(\"Descargando {} imagenes en \\n[{}]\".format(len(ilist), path))\n\n iqueue = queue.Queue()\n oqueue = queue.Queue()\n\n threads = []\n for i in range(4):\n thr = threading.Thread(target=subprocess, args=(iqueue, oqueue))\n thr.daemon = True\n thr.start()\n threads.append(thr)\n\n for img in ilist:\n if not img[0]:\n continue\n\n link = img[0]\n name = img[1]\n if img[2]:\n name = img[2]\n iqueue.put((link, os.path.join(path, name)))\n\n f = 0\n i = 0\n try:\n while i < len(ilist):\n while not oqueue.empty():\n r = oqueue.get()\n \n print(\"\\r...\" + r[0][8:], end=\" \")\n if not r[1]:\n print(\"[FAILED]\", end=\"\")\n f += 1\n print()\n i += 1\n\n print(\"\\r{}Kb\".format(nbits >> 10), end=\"\")\n time.sleep(0.15)\n except KeyboardInterrupt:\n exit()\n\n print(\"\\r{}Kb\".format(nbits >> 10))\n print(\"Terminado: archivos descargados {}, errores {}\".format(i - f, f))usage = \"\"\"\nUso: %s [opciones] <url del hilo o tablon/hilo> [<destino>]\nOpciones:\n -no-subfolder Omite la creacion de una subcarpeta para las imagenes.\n -overwrite Sobrescribe los archivos con el mismo nombre.\n -update Solo descarga los archivos que no existen.\n\"\"\" % sys.argv[0]def showusage():\n print(usage)\n exit()if [u]name[/u] == \"[u]main[/u]\":\n if len(sys.argv) < 2:\n showusage()\n sys.argv.pop(0)\n args = sys.argv\n\n # parametros\n options = {\n \"-no-subfolder\": (\"subfolder\", True),\n \"-overwrite\": (\"overwrite\", False),\n \"-update\": (\"update\", False)\n }\n\n s = globals()\n for option in options:\n m = options[option]\n s[m[0]] = m[1]\n\n while args[0] in options:\n a = args.pop(0)\n if not options[a]: # parametro duplicado\n showusage()\n s[options[a][0]] = not options[a][1]\n options[a] = None\n\n if not args or len(args) > 2:\n showusage()\n\n r = getthreadinfo(args.pop(0))\n if not r:\n print(\"Error: url invalida\")\n\n url = \"https://hispachan.org/{}/res/{}.html\".format(r[0], r[1])\n try:\n ilist = getimglist(url)\n if not ilist:\n print(\"Error: ningun archivo para descargar\")\n exit()\n\n dpath = os.getcwd()\n if args:\n dpath = args[0]\n #\n if subfolder:\n dpath = os.path.join(dpath, r[0], r[1])\n saveimages(ilist, dpath)\n except KeyboardInterrupt:\n exit()\n except Exception as e:\n print(\"Error:\", e)[/code]\n>>38877\n>muchas barras invertidas. \nSe pueden omitir las que escapan el / ya que en Python están de mas." | renderPostMessage 40509}}} |
| >> | {{{">>40509\nNo importa. Hay un error (falta el exit()):\n[code]\n r = getthreadinfo(args.pop(0))\n if not r:\n print(\"Error: url invalida\")\n[/code]" | renderPostMessage 40510}}} |
| >> | {{{">>40510\nCorregido, aunque quite ese if y la función getthreadinfo() quedo así:\n[code]def getthreadinfo(url):\n if enlace.match(url) == None:\n print(\"Error: url invalida\")\n exit(1)\n board, thread = enlace.match(url).groups()\n return (board, thread)[/code]" | renderPostMessage 40514}}} |
| >> | {{{">>40514\nEstas llamando a \"match\" dos veces ¿Por qué no hqaces esto?:\n[code]\ndef getthreadinfo(url):\n r = enlace.match(url)\n if r:\n return r.groups()\n print(\"Error: url invalida\")\n exit(1)\n[/code]" | renderPostMessage 40517}}} |
| >> | {{{">>40509\nAquí OP, ya te aprobé los dos PR, gracias por contribuir, estaba pensando en armarle un front a el script de node.js, (no domino mucho python), así que te invito a realizarle alguna GUI para que sea mas amigable ;), asi zeta quizás nos haga el scraper oficial de hispa xd" | renderPostMessage 40518}}} |
| >> | {{{">>40517\nPor que la idea era hacerlo funcionar y no me detuve mucho a pensar en esos detalles. Quizás después incluya esa corrección junto con lo de >>39458 (aunque también eres libre de enviarle un pull request a OP).\n>>40518\n>estaba pensando en armarle un front al script de node.js\nPodrías ver si el anon que hizo lo de >>36958 le interesa publicar el código fuente de esa pagina (al menos la parte del frontend) pero a simple vista parece estar hecha con Bootstrap. Sino quizás alcance con copiar el HTML y los scripts para tener una instancia propia.\n>te invito a realizarle alguna GUI para que sea mas amigable\nSeria un proyecto interesante (ya sea un programa nativo o una webapp con Django), por desgracia últimamente no tengo mucho tiempo libre debido a mi trabajo, aunque si alguien tiene otras ideas o mejoras para el script pueden dejarlas aquí y las agregare en cuanto me sea posible." | renderPostMessage 41403}}} |
| >> | {{{"Actualización del script en Python:\n[code]# -*- coding: utf-8 -*-\nimport sys\nimport os\nimport re\nimport threading\nimport queue\nimport time\nimport gettext\n\nimport urllib.request\nimport urllib.error\n\nURLError = urllib.error.URLError\n\n# flags\nsubfolder = None\noverwrite = None\nupdate = None\ndebug = None\n\n# shared stuff\nnbitsmutx = threading.Lock()\nnbits = 0\n\n# Expresiones regulares para evitar escribir código innecesariamente complejo\nadjuntos = re.compile('<span class=\"file(?:namereply|size)\">[\\r\\n]+<a[\\s\\r\\n]+target=\"_blank\"[\\s\\r\\n]+href=\"([^\"]+)\"(?:[\\s\\S]*?)<span class=\"nombrefile\"(?:>, ([^<]+)| title=\"([^\"]+))')\n# Detecta el tablón e ID del hilo de un enlace completo o en la forma corta: \"/tablón/hilo\". \nenlace = re.compile(\"(?i)^(?:(?:(?:(?:https?://)?(?:[a-z]+[.])?)?hispachan[.]org/)?|/?)?([a-z]+)/(?:res/)?([0-9]+)(?:[.]html)?\")\n\ndef getthreadinfo(url):\n r = enlace.match(url)\n if r:\n return r.groups()\n print(\"Error: url invalida\")\n exit(1)\n\ndef getimglist(url):\n opener = urllib.request.build_opener()\n opener.addheaders = [\n ('User-agent', 'Mozilla/5.0')\n ]\n try:\n f = opener.open(url, timeout=20)\n b = f.read()\n except URLError as e:\n raise e\n f.close()\n\n return adjuntos.findall(b.decode('utf-8'))\n\ndef subproc(iqueue, oqueue):\n while True:\n tmp = iqueue.get()\n if not tmp:\n break\n\n if saveimg(tmp[0], tmp[1]):\n oqueue.put((tmp[0], True))\n continue\n oqueue.put((tmp[0], False))\n\ndef saveimg(url, path):\n global nbits\n global nbitsmutx\n\n opener = urllib.request.build_opener()\n opener.addheaders = [\n ('User-agent', 'Mozilla/5.0')\n ]\n try:\n f = opener.open(url, timeout=120)\n except URLError as e:\n if debug == True: raise e\n else: return False\n except Exception as e:\n if debug == True: raise e\n else: return False\n\n if os.path.isfile(path):\n if update:\n try:\n sz1 = int(f.info()[\"Content-Length\"])\n\n fh = open(path, \"rb\")\n fh.seek(0, 2)\n sz2 = fh.tell()\n fh.close()\n except Exception as e:\n if debug == True: raise e\n else: return False\n\n if sz1 == sz2:\n return True\n\n # si el archivo existe intentamos con un nuevo nombre\n if not update and not overwrite:\n fnme, fext = os.path.splitext(path)\n\n i = 1\n while os.path.isfile(path):\n path = fnme + \"(\" + str(i) +\")\" + fext\n i += 1\n\n try:\n fh = open(path, \"wb\")\n while True:\n b = f.read(4096)\n if not b:\n break\n\n nbitsmutx.acquire()\n nbits += len(b)\n nbitsmutx.release()\n\n fh.write(b)\n fh.close()\n except (IOError, URLError) as e:\n if debug == True: raise e\n else: return False\n except Exception as e:\n if debug == True: raise e\n else: return False\n return True\n\ndef saveimages(ilist, dpath):\n global nbits\n\n path = os.path.abspath(dpath)\n try:\n os.makedirs(path)\n except FileExistsError:\n pass\n\n print(\"Descargando {} imágenes en \\n[{}]\".format(len(ilist), path))\n\n iqueue = queue.Queue()\n oqueue = queue.Queue()\n\n threads = []\n for i in range(4):\n thr = threading.Thread(target=subproc, args=(iqueue, oqueue))\n thr.daemon = True\n thr.start()\n threads.append(thr)\n\n for img in ilist:\n if not img[0]:\n continue\n\n link = img[0]\n name = img[1]\n if img[2]:\n name = img[2]\n iqueue.put((link, os.path.join(path, name)))\n\n f = 0\n i = 0\n try:\n while i < len(ilist):\n while not oqueue.empty():\n r = oqueue.get()\n \n print(\"\\r...\" + r[0][8:], end=\" \")\n if not r[1]:\n print(\"[FAILED]\", end=\"\")\n f += 1\n print()\n i += 1\n\n print(\"\\r{}Kb\".format(nbits >> 10), end=\"\")\n time.sleep(0.15)\n except KeyboardInterrupt:\n exit(1)\n\n print(\"\\r{}Kb\".format(nbits >> 10))\n print(\"Terminado: archivos descargados {}, errores {}\".format(i - f, f))\n\n# Traducimos algunos mensajes, para agregar mas idiomas véase también https://stackoverflow.com/questions/22951442/how-to-make-pythons-argparse-generate-non-english-text/28836537#28836537\ndef convertArgparseMessages(s):\n subDict = \\\n {'positional arguments':'Argumentos posicionales',\n 'optional arguments':'Argumentos opcionales',\n 'usage: ':'Uso: ',\n 'the following arguments are required: %s':'los siguientes parámetros son requeridos: %s'\n #'show this help message and exit':'Affiche ce message et quitte'\n }\n if s in subDict:\n s = subDict[s]\n return s\n\ngettext.gettext = convertArgparseMessages\nimport argparse\n\nif [u]name[/u] == \"[u]main[/u]\":\n parser = argparse.ArgumentParser(add_help=False, description=('Descarga los archivos adjuntos de un hilo de Hispachan.'))\n parser.add_argument('url', help='Enlace del hilo o identificador en la forma \"tablón/hilo\".')\n parser.add_argument('destino', nargs='?', help='Directorio en donde se guardaran los archivos (por defecto se descargan en el directorio actual).', default=os.getcwd())\n parser.add_argument( '-h', '-help', action='help', default=argparse.SUPPRESS, help='Muestra este mensaje de ayuda y sale.')\n parser.add_argument('-n', '-no-subfolder', dest='subfolder', help='Omite la creación de una subcarpeta para las imágenes.', default=True, action='store_false')\n parser.add_argument('-o', '-overwrite', dest=\"overwrite\", help='Sobrescribe los archivos con el mismo nombre.', default=False, action='store_true')\n parser.add_argument('-u', '-update', dest=\"update\", help='Solo descarga los archivos que no existen.', default=False, action='store_true')\n parser.add_argument('-d', '-debug', dest=\"debug\", help='Dispara las excepciones para facilitar la detección de bugs.', default=False, action='store_true')\n\n # Si no hay enlace entonces se muestra la ayuda y sale\n if len(sys.argv)==1:\n parser.print_help()\n sys.exit(1)\n \n args = parser.parse_args(sys.argv[1:])\n \n # Asignamos algunas variables globales predefinidas en el script\n s = globals()\n for option in [\"subfolder\", \"overwrite\", \"update\", \"debug\"]:\n s[option] = getattr(args, option)\n\n r = getthreadinfo(args.url)\n\n url = \"https://hispachan.org/{}/res/{}.html\".format(r[0], r[1])\n try:\n ilist = getimglist(url)\n if not ilist:\n print(\"error: ningún archivo para descargar\")\n exit()\n\n dpath = args.destino\n \n if subfolder:\n dpath = os.path.join(dpath, r[0], r[1])\n \n saveimages(ilist, dpath)\n except KeyboardInterrupt:\n exit(1)\n except Exception as e:\n if debug == True: raise e\n else: print(\"error:\", e)[/code]\nEl cambio mas notorio es la incorporación del modulo argparse ( https://docs.python.org/3/library/argparse.html ) para el manejo de las opciones de la linea de comandos en lugar de hacerlo de forma \"espartana\" como hasta ahora (se supone que ese modulo esta incluido en Python, por lo que el script sigue manteniéndose sin dependencias externas y tan simple como es posible).\nEn https://github.com/josevenezuelapadron/hispachan-scraping/pull/6 se pueden ver otros cambios y correcciones menores que hice." | renderPostMessage 42498}}} |
| >> | {{{">>42498\nmuchas gracias por seguir invirtiendo tu tiempo en el desarrollo del repo, gracias, ya acepte tu PR" | renderPostMessage 42504}}} |
| >> | {{{">>42498\n>el script sigue manteniéndose sin dependencias externas y tan simple como es posible\nWow. Ahora que usas argparse en vez de reducir el código y simplificarlo has agregado complejidad. Cheers." | renderPostMessage 42505}}} |
| >> | {{{">>42505\n¿Complejidad donde? Es preferible usar algo que ya esta hecho como argparse antes que estar [s]reinventando la rueda[/s] procesando los parámetros a mano, con el añadido de que así el código se entiende mejor que con lo que había antes.\nY si tanto te arde el culo te invito a hacer un parser de argumentos que permita usar tanto opciones cortas como largas igual que en el script y que sea tan intuitivo como argparse (o que al menos este mínimamente documentado para que otros además de ti puedan entender como funciona).\nEso si, tampoco creo que el script sea perfecto y que lo de gettext esta de mas, pero parece que lo metieron para traducir un par de cadenas en argparse." | renderPostMessage 43261}}} |
| >> | {{{">>43261\n>Es preferible usar algo que ya esta hecho como argparse antes que estar reinventando la rueda procesando los parámetros a mano, con el añadido de que así el código se entiende mejor que con lo que había antes.\nNo. Justamente tenes que leer la documentación para saber como funciona argparse.\n\n>Y si tanto te arde el culo te invito a hacer un parser de argumentos que permita usar tanto opciones cortas como largas igual que en el script y que sea tan intuitivo como argparse (o que al menos este mínimamente documentado para que otros además de ti puedan entender como funciona).\nNo me quejo de argparse, me quejo de la utilización de argparse en un script tan simple ¿Necesitas opciones cortas? ¿Necesitas autodocumentar los parámetros?\n\n>Eso si, tampoco creo que el script sea perfecto y que lo de gettext esta de mas, pero parece que lo metieron para traducir un par de cadenas en argparse.\nCompletamente innecesario." | renderPostMessage 43262}}} |
| >> | {{{">>42505\nargparse es una biblioteca base de Python negro" | renderPostMessage 43276}}} |
| >> | {{{">>43276\n>Biblioteca\n>No librería\nEso no importa, la complejidad es mayor. Tal vez sea mi culpa, pero no veo como usar argparse es una mejora, honestamente prefiero usar lo menos posible la extensa librería que ofrece Python." | renderPostMessage 43291}}} |
| >> | 155805405442.png [Google] [ImgOps] [iqdb] [SauceNAO] ( 166.77KB, 802x684, Captura de pantalla 2019-05-16 a las 20_46_48.png )  {{{">>43291\n>libreria\n>no biblioteca" | renderPostMessage 43293}}} |
| >> | {{{">>43293\nNo estamos hablando de libros. Prefiero librería es más corto y se parece al termino en inglés." | renderPostMessage 43299}}} |
| >> | {{{">>43262\n>tienes que leer la documentación para saber como funciona argparse.\nSolo para cosas concretas, la mayoría de las veces alcanza con hacer copia y pega de los parámetros que tienen otros scripts. Además, con argparse se puede intuir a golpe de vista lo que hace a diferencia de este bloque de código:\n[code] s = globals()\n for option in options:\n m = options[option]\n s[m[0]] = m[1]\n\n while args[0] in options:\n a = args.pop(0)\n if not options[a]: # parametro duplicado\n showusage()\n s[options[a][0]] = not options[a][1]\n options[a] = None[/code]\nQue si bien obtiene los parámetros y actualiza las variables globales según su contenido, no es ni de lejos tan intuitivo como argparse.\n>un script tan simple \n>descargas en paralelo usando hilos\nElige solo una.\n>>43291\n>honestamente prefiero usar lo menos posible la extensa librería que ofrece Python\n¿Por que?, puedo entenderlo con módulos de terceros pero no veo que tiene de malo aprovechar lo que Python ya te da hecho (y muchas veces mejor implementado que lo que uno puede inventarse por su cuenta) a menos que sea por cuestiones de aprendizaje y cosas por el estilo." | renderPostMessage 44019}}} |
| >> | {{{">>44019\n>con argparse se puede intuir a golpe de vista lo que hace a diferencia de este bloque de código\nNo veo el problema, es solo manipulación de diccionarios y listas. No es tan difícil de entender.\n\n>no es ni de lejos tan intuitivo como argparse.\nEs un hack.\n\n>¿Por que?, puedo entenderlo con módulos de terceros pero no veo que tiene de malo aprovechar lo que Python ya te da hecho \nNada de malo, solo lo hago por autismo y si puedo reemplazar las funciones de un modulo con solo 10 lineas de código y tener la misma funcionalidad entonces es bueno." | renderPostMessage 44023}}} |
| >> | {{{"Nueva actualización del script en Python:\n[code]# -*- coding: utf-8 -*-\nfrom [u]_[/u]_future[u]_[/u]_ import print_function\nimport sys\nimport os\nimport re\nimport threading\nimport queue\nimport time\nimport gettext\n\nif sys.version_info.major == 2:\n from urllib2 import build_opener, URLError\nelse:\n from urllib import request\n import urllib.error\n \n build_opener = urllib.request.build_opener\n URLError = urllib.error.URLError \n\n# flags\nsubfolder = None\noverwrite = None\nupdate = None\ndebug = None\n\n# shared stuff\nnbitsmutx = threading.Lock()\nnbits = 0\n\n# Expresiones regulares para evitar escribir código innecesariamente complejo\nadjuntos = re.compile('<span class=\"file(?:namereply|size)\">[\\r\\n]+<a[\\s\\r\\n]+target=\"_blank\"[\\s\\r\\n]+href=\"([^\"]+)\"(?:[\\s\\S]*?)<span class=\"nombrefile\"(?:>, ([^<]+)| title=\"([^\"]+))')\n# Detecta el tablón e ID del hilo de un enlace completo o en la forma corta: \"/tablón/hilo\". \nenlace = re.compile(\"(?i)^(?:(?:(?:(?:https?://)?(?:[a-z]+[.])?)?hispachan[.]org/)?|/?)?([a-z]+)/(?:res/)?([0-9]+)(?:[.]html)?\")\n\n# Dispara la excepcion o devuelve False dependiendo en base al parametro debug\ndef debugger(excepcion, show_exception = False):\n if debug == True: raise excepcion\n else:\n if show_exception == True: print(\"error:\", e)\n return False\n\n# Devuelve un objeto para manejar peticiones HTTP o False en caso de una excepcion\ndef url_opener(url, time_out):\n useragent = 'Mozilla/5.0'\n opener = build_opener()\n opener.addheaders = [\n ('User-agent', useragent)\n ]\n try:\n return opener.open(url, timeout=time_out)\n except URLError as e:\n debugger(e)\n except Exception as e:\n debugger(e)\n\ndef getthreadinfo(url):\n r = enlace.match(url)\n if r:\n return r.groups()\n print(\"Error: url invalida\")\n exit(1)\n\ndef getimglist(url):\n f = url_opener(url, 20)\n b = f.read()\n f.close()\n\n return adjuntos.findall(b.decode('utf-8'))\n\ndef subproc(iqueue, oqueue):\n while True:\n tmp = iqueue.get()\n if not tmp:\n break\n\n if saveimg(tmp[0], tmp[1]):\n oqueue.put((tmp[0], True))\n continue\n oqueue.put((tmp[0], False))\n\ndef saveimg(url, path):\n global nbits\n global nbitsmutx\n\n f = url_opener(url, 120)\n\n if os.path.isfile(path):\n if update:\n try:\n sz1 = int(f.info()[\"Content-Length\"])\n\n fh = open(path, \"rb\")\n fh.seek(0, 2)\n sz2 = fh.tell()\n fh.close()\n except Exception as e:\n debugger(e)\n\n if sz1 == sz2:\n return True\n\n # si el archivo existe intentamos con un nuevo nombre\n if not update and not overwrite:\n fnme, fext = os.path.splitext(path)\n\n i = 1\n while os.path.isfile(path):\n path = fnme + \"(\" + str(i) +\")\" + fext\n i += 1\n\n try:\n fh = open(path, \"wb\")\n while True:\n b = f.read(4096)\n if not b:\n break\n\n nbitsmutx.acquire()\n nbits += len(b)\n nbitsmutx.release()\n\n fh.write(b)\n fh.close()\n except (IOError, URLError) as e:\n debugger(e)\n except Exception as e:\n debugger(e)\n return True\n\ndef saveimages(ilist, dpath):\n global nbits\n\n path = os.path.abspath(dpath)\n try:\n os.makedirs(path)\n except OSError as e:\n if e.errno == os.errno.EEXIST:\n print('El directorio %s ya se habia creado con anterioridad' % dpath)\n else:\n raise\n\n print(\"Descargando {} imágenes en \\n[{}]\".format(len(ilist), path))\n\n iqueue = queue.Queue()\n oqueue = queue.Queue()\n\n threads = []\n for i in range(4):\n thr = threading.Thread(target=subproc, args=(iqueue, oqueue))\n thr.daemon = True\n thr.start()\n threads.append(thr)\n\n for img in ilist:\n if not img[0]:\n continue\n\n link = img[0]\n name = img[1]\n if img[2]:\n name = img[2]\n iqueue.put((link, os.path.join(path, name)))\n\n f = 0\n i = 0\n try:\n while i < len(ilist):\n while not oqueue.empty():\n r = oqueue.get()\n \n print(\"\\r...\" + r[0][8:], end=\" \")\n if not r[1]:\n print(\"[FAILED]\", end=\"\")\n f += 1\n print()\n i += 1\n\n print(\"\\r{}Kb\".format(nbits >> 10), end=\"\")\n time.sleep(0.15)\n except KeyboardInterrupt:\n exit(1)\n\n print(\"\\r{}Kb\".format(nbits >> 10))\n print(\"Terminado: archivos descargados {}, errores {}\".format(i - f, f))\n\ndef convertArgparseMessages(s):\n subDict = \\\n {'positional arguments':'Argumentos posicionales',\n 'optional arguments':'Argumentos opcionales',\n 'usage: ':'Uso: ',\n 'the following arguments are required: %s':'los siguientes parámetros son requeridos: %s'\n #'show this help message and exit':'Affiche ce message et quitte'\n }\n if s in subDict:\n s = subDict[s]\n return s\n\ngettext.gettext = convertArgparseMessages\nimport argparse\n\nif [u]name[/u] == \"[u]main[/u]\":\n parser = argparse.ArgumentParser(add_help=False, description=('Descarga los archivos adjuntos de un hilo de Hispachan.'))\n parser.add_argument('url', help='Enlace del hilo o identificador en la forma \"tablón/hilo\".')\n parser.add_argument('destino', nargs='?', help='Directorio en donde se guardaran los archivos (por defecto se descargan en el directorio actual).', default=os.getcwd())\n parser.add_argument( '-h', '-help', action='help', default=argparse.SUPPRESS, help='Muestra este mensaje de ayuda y sale.')\n parser.add_argument('-n', '-no-subfolder', dest='subfolder', help='Omite la creación de una subcarpeta para las imágenes.', default=True, action='store_false')\n parser.add_argument('-o', '-overwrite', dest=\"overwrite\", help='Sobrescribe los archivos con el mismo nombre.', default=False, action='store_true')\n parser.add_argument('-u', '-update', dest=\"update\", help='Solo descarga los archivos que no existen.', default=False, action='store_true')\n parser.add_argument('-d', '-debug', dest=\"debug\", help='Dispara las excepciones para facilitar la detección de bugs.', default=False, action='store_true')\n\n # Si no hay enlace entonces se muestra la ayuda y sale\n if len(sys.argv)==1:\n parser.print_help()\n sys.exit(1)\n \n args = parser.parse_args(sys.argv[1:])\n \n # Asignamos algunas variables globales predefinidas en el script\n s = globals()\n for option in [\"subfolder\", \"overwrite\", \"update\", \"debug\"]:\n s[option] = getattr(args, option)\n\n r = getthreadinfo(args.url)\n\n url = \"https://hispachan.org/{}/res/{}.html\".format(r[0], r[1])\n try:\n ilist = getimglist(url)\n if not ilist:\n print(\"error: ningún archivo para descargar\")\n exit()\n\n dpath = args.destino\n \n if subfolder:\n dpath = os.path.join(dpath, r[0], r[1])\n \n saveimages(ilist, dpath)\n except KeyboardInterrupt:\n exit(1)\n except Exception as e:\n debugger(e, True)[/code]\nEn esta ocasión no implemente ninguna funcionalidad nueva ni hice cambios [s]demasiado[/s] notorios, solo le agregue compatibilidad con Python 2 y limpie algo de código repetido. Como de costumbre los detalles de los cambios se pueden leer en https://github.com/josevenezuelapadron/hispachan-scraping/pull/7\n>>42505\n>>43262\n>>43291\n>>44023\nLo siento pero argparse se queda (y [u]_[/u]_future[u]_[/u]_ también por cierto), a menos que me des una buena razón para no usarlo mas allá de \"muh complejidad\" (lo cual es subjetivo, además, ni que se estuvieran violando los principios de https://es.wikipedia.org/wiki/Zen_de_Python )." | renderPostMessage 44960}}} |
| >> | {{{">>44960\nAqui OP, ya acepté tus PR, nuevamente gracias por seguir dandole soporte al script, yo tengo el mio (JS) olvidado, veré si en estos dias le hago mantenimiento" | renderPostMessage 44968}}} |
| >> | {{{">>44960\nEl Zen de Python está orientado a mogólicos lo importante es seguir la reglas de formato de código del pep8 y no ser un mogólico.\nPython 2 está prácticamente en desuso, menos de 16% ATM (fuente: mi culo), no es esperable que los usuarios de Python 2 se incrementen, todo lo contrario." | renderPostMessage 44984}}} |
| >> | {{{">>40518\n>GUI\n¿Alguna idea o mockup para saber como se debería implementar de cara al usuario? Viendo que ya muchos deben estar de vacaciones (dependiendo del país) quizás alguien por aquí lo tome como proyecto personal para pasar el tiempo o algo así." | renderPostMessage 45693}}} |
| >> | {{{">>45693\nAquí OP, creo que algo muy sencillo y básico estaría bien, es un programa para bajar fotos y vídeos de un hilo, no una red social" | renderPostMessage 45709}}} |
| >> | {{{"Yo no estoy en desacuerdo con el uso de argparse (aunque yo personalmente no lo uso, ni usaría en mis proyectos) pero sí estoy en desacuerdo con el uso de threads. Me parece innecesario." | renderPostMessage 45713}}} |
| >> | {{{">>45713\nEn teoría debería ser más rápido con threads (debería haber usado asyncio). Nunca lo probé, pero se pierde mucho tiempo entre cada request al servidor." | renderPostMessage 45716}}} |
| >> | {{{">>45716\n>mas rapido\nÑo, más reactivo. Con un solo hilo la app se bloqueará entre petición y petición." | renderPostMessage 45738}}} |
| >> | {{{">>45716\n\nEstoy de acuerdo contigo que crear la conexión tiene su overhead, pero pienso que no tiene tanto impacto a menos que te topes con el worst case scenario. Por ejemplo bajar decenas de archivos muy pequeños, donde el overhead de crear la conexión tenga más impacto relativo a lo que te tardas bajando, digamos, 5KB.\n\nPero bueno, ya está hecho y funciona." | renderPostMessage 45778}}} |
| >> | {{{">>36592\nOP no sabe lo que quiere" | renderPostMessage 45812}}} |
| >> | {{{">sudo chmod +x index.js\n>sudo ./index.js\n\nRealmennte espero que nadie sea tan pendejo para correr tu mierda hecha en Node con sudo." | renderPostMessage 45813}}} |