
Version 0.2.5
>>53153
Los tres tipos parecen los pillar men kek
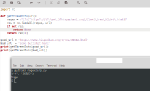
>>38824
¿Por qué odias tanto las expresiones regulares? ¿Eres el mongol del hilo de Vim que argumentaba que no son buenas porque "son complicadas"? Tu función getthreadinfo() podría simplificarse ampliamente.

>>65667
>>92756
> el futuro es ahora
Hispachan es para mayores de edad.

>>65712
Siempre me pareció escalofriante que Banana Joe tuviera un segundo rostro en el trasero.
Tobías es menos carismático.
>Ese episodio cuando, encuentran a Banana Joe viendo porno
>>38688
Añadido los request/descargas en paralelo y la flag "-update" para actualizar los archivos en algún hilo.
# -*- coding: utf-8 -*-
import sys
import os
import re
import threading
import queue
import time
import urllib.request
import urllib.parse
import urllib.error
URLError = urllib.error.URLError
# flags
subfolder = None
overwrite = None
update = None
# shared stuff
nbitsmutx = threading.Lock()
nbits = 0
def getthreadinfo(url):
# https://www.hispachan.org/xx/res/xx.html
if not url:
return None
r = urllib.parse.urlparse(url.lower())
s = r.netloc
if not (s.startswith("www.hispachan.org") or s.startswith("hispachan.org")):
f = url.split("/")
if len(f) == 2:
return f
return None
f = r.path.split("/")
if len(f) != 4:
return None
if f[2] != "res":
return None
board = f[1]
thread = f[3].split(".")[0]
if not (board or thread):
return None
return (board, thread)
def getimglist(url):
imglist = []
opener = urllib.request.build_opener()
opener.addheaders = [
('User-agent', 'Mozilla/5.0')
]
try:
f = opener.open(url, timeout=20)
b = f.read()
except URLError:
raise
f.close()
i = 0
while 1:
try:
i = b.index(b"", i + 1)
except ValueError:
break
imglist.append(i)
cname = re.compile(b'href="[^=]+(hispachan.org.+.src.(.+.+))"')
rname = re.compile(b'<.+class="nombrefile"(?: title="(.+)")?>.?\s+(.+)<.+>')
for i in range(len(imglist)):
name1 = cname.search(b, imglist[i], imglist[i]+1024)
name2 = rname.search(b, imglist[i], imglist[i]+1024)
r = [None, None, None]
if name1:
r[0] = name1.group(1).decode("utf-8")
r[1] = name1.group(2).decode("utf-8")
if name2:
if name2.group(1):
r[2] = name2.group(1).decode("utf-8")
else:
r[2] = name2.group(2).decode("utf-8")
imglist[i] = r
return imglist
def subprocess(iqueue, oqueue):
while True:
tmp = iqueue.get()
if not tmp:
break
if saveimg(tmp[0], tmp[1]):
oqueue.put((tmp[0], True))
continue
oqueue.put((tmp[0], False))
def saveimg(url, path):
global nbits
global nbitsmutx
opener = urllib.request.build_opener()
opener.addheaders = [
('User-agent', 'Mozilla/5.0')
]
try:
f = opener.open(url, timeout=120)
except URLError:
return False
except:
return False
if os.path.isfile(path):
if update:
try:
sz1 = int(f.info()["Content-Length"])
fh = open(path, "rb")
fh.seek(0, 2)
sz2 = fh.tell()
fh.close()
except:
return False
if sz1 == sz2:
return True
# si el archivo existe intentamos con un nuevo nombre
if not update and not overwrite:
fnme, fext = os.path.splitext(path)
i = 1
while os.path.isfile(path):
path = fnme + "(" + str(i) +")" + fext
i += 1
try:
fh = open(path, "wb")
while True:
b = f.read(4096)
if not b:
break
nbitsmutx.acquire()
nbits += len(b)
nbitsmutx.release()
fh.write(b)
fh.close()
except (IOError, URLError):
return False
except:
return False
return True
def saveimages(ilist, dpath):
global nbits
path = os.path.abspath(dpath)
try:
os.makedirs(path)
except FileExistsError:
pass
print("Descargando {} imagenes en \n[{}]".format(len(ilist), path))
iqueue = queue.Queue()
oqueue = queue.Queue()
threads = []
for i in range(4):
thr = threading.Thread(target=subprocess, args=(iqueue, oqueue))
thr.daemon = True
thr.start()
threads.append(thr)
for img in ilist:
if not img[0]:
continue
link = "https://"; + img[0]
name = img[1]
if img[2]:
name = img[2]
iqueue.put((link, os.path.join(path, name)))
f = 0
i = 0
try:
while i < len(ilist):
while not oqueue.empty():
r = oqueue.get()
print("\r..." + r[0][8:], end=" ")
if not r[1]:
print("[FAILED]", end="")
f += 1
print()
i += 1
print("\r{}Kb".format(nbits >> 10), end="")
time.sleep(0.15)
except KeyboardInterrupt:
exit()
print("\r{}Kb".format(nbits >> 10))
print("Terminado: archivos descargados {}, errores {}".format(i - f, f))
usage = """
Uso: thisscript.py [opciones][ ]
Opciones:
-no-subfolder Omite la creacion de una subcarpeta para las imagenes.
-overwrite Sobrescribe los archivos con el mismo nombre.
-update Solo descarga los archivos que no existen.
"""
def showusage():
print(usage)
exit()
if name == "main":
if len(sys.argv) < 2:
showusage()
sys.argv.pop(0)
args = sys.argv
# parametros
options = {
"-no-subfolder": ("subfolder", True),
"-overwrite": ("overwrite", False),
"-update": ("update", False)
}
s = globals()
for option in options:
m = options[option]
s[m[0]] = m[1]
while args[0] in options:
a = args.pop(0)
if not options[a]: # parametro duplicado
showusage()
s[options[a][0]] = not options[a][1]
options[a] = None
if not args or len(args) > 2:
showusage()
r = getthreadinfo(args.pop(0))
if not r:
print("Error: url invalida")
url = "https://hispachan.org/{}/res/{}.html".format(r[0], r[1])
try:
ilist = getimglist(url)
if not ilist:
print("Error: ningun archivo para descargar")
exit()
dpath = os.getcwd()
if args:
dpath = args[0]
#
if subfolder:
dpath = os.path.join(dpath, r[0], r[1])
saveimages(ilist, dpath)
except KeyboardInterrupt:
exit()
except Exception as e:
print("Error:", e)

>>65696
>quejarse de pecar de autista una serie que nació precisamente para ser autista
>>65698
>banana joe
¿En serio? Es el personaje menos carismático y molesto de la serie. Preferiría mil veces un spin-off de Sussie antes que medio segundo de spin-off de banana joe

Oigan, anons, ya casi es Lunes ¿Ya tienen pensado con qué imagen abrir el palolunes de mañana? Recuerden llamar gente de /g/ para ver si alguien se une a nuestro autismo de niñitas con ojos de punto.
Alguien sabe de buenos juegos para Android? Ya no tengo PC
>>65696
>esa mierda solo la ven los underages ahora.
¿Estas seguro? El Gumball moderno no es más que memes de Tumblr y Devian y le-gumball-face.png, así que lo dudo bastante.
>Esa monita es un personaje totalmente de relleno.
¿Por qué crees que hablé de los personajes de fondo? La gracia del capítulo de Clare es que algunos personajes de Background son incluso más interesantes que los propios protagonistas, tema que había sido tocado con anterioridad, en el episodio de los objetos:
https://youtu.be/KTs1tR1yspY
 Hispachan Files
Hispachan Files